소이뉴스는 내년에도 열심히 노력하겠습니다. 안녕하세요, 구독자님.
이번 한 주도 행복하게 보내고 계신가요?
'꿈'...
'꿈'이란 단어는 두 가지의 의미를 갖고 있습니다. 하나는 잠 잘 때 나타나는 정신현상을, 또 다른 하나는 이루고자 하는 목표나 희망 등이 그것입니다. 이 둘은 얼핏 보기엔 전혀 다른 성격이지만 유사한 점도 있습니다. 차이점이라고 하면 전자는 비현실적인 상상 속 세계 속에서 제한없는 가능성과 규칙성 없는 경험을, 후자는 현실적이고 실현가능한 것을 현실적인 제약과 계획을 통해 달성하려 한다는 것을 들 수 있겠죠. 유사한 측면은 둘 다 자신의 욕망을 반영하고 상상력, 창의력을 확장시키는 역할을 하며 결과적으로 사람의 심리와 행동에 영향을 미친다는 것입니다.
제 경우만 그런지는 모르겠지만, 잠에서 깨고 난 즉시는 꿈속 내용이 기억나지만 채 1분이 지나기 전에 그 기억이 사라지는 경우가 많습니다. 주변 사람들 가운데 꿈 내용을 생생하게 기억하는 사람이 있는데 저는 그 분이 너무 부럽습니다. 어떤 글에서 보니 비렘수면 단계에서 꾼 꿈은 선명성이 낮아 기억하지 못하는 경우가 많다고 했는데 그 논리로 본다면 제가 깊은 잠을 못 잔다는 말이 되기 때문이죠. 목표인 꿈 또한 초기에 설정한 것을 달성하려는 노력을 지속하는 것이 시간이 지날수록 어려워져 포기하게 되는 경우가 많죠. 이렇듯 두 꿈은 모두 시간적인 한계를 가지고 있다고도 할 수 있습니다. 하지만, 잊지 않으려고 자꾸 입속에 되뇌이더라도, 필기도구를 찾아 기록할 시간조차 허용해 주지 않는 뇌세포의 무정함을 가진 전자보다, 후자는 진행상황을 봐가며 중간중간 주변의 도움이나 시도하는 방식을 바꿔가며 그 한계를 넘어설 기회가 있으니 더 낫긴 한 것 같습니다.
이왕 나왔으니 잠잘 때 꾸는 꿈에 대해 조금만 더 얘기를 해 보겠습니다. 사람의 하룻밤 잠은 비렘수면(얕은 수면 1,2단계 → 깊은 수면 3,4단계) → 렘수면으로 이어지는 수면주기를 3~5차례 거친다고 합니다. 잠자는 동안 뇌는 낮에 학습한 정보들을 분류,필터링 및 저장하고 동시에 노속에 쌓인 노폐물을 처리하는데 뇌세포의 시냅스들이 다음 날 다시 장사(?)를 할 수 있도록 준비하는 것이라고 보면 될 것 같습니다.
이 가운데 렘수면(REM: Rapid Eye Movement)의 특징은 용어 그대로 빠른 안구운동이 일어난다는 것인데 이때 대부분 꿈을 꾸게 됩니다. 꿈 꾸는 동안 뇌는 기억을 형성, 재구성하는 작업을 하게 되는데 그러다보니 예상과는 달리 활발히 활동하는 낮의 각성상태와 유사한 뇌파 활동을 보입니다. 대신 팔과 다리근육 등은 일시적으로 마비가 되죠. 뇌는 깨어있지만 몸은 수면 중인 그런 상황인데 혹시 자다가 가위눌린 경험을 해 보신 분은 이해하실 수 있을 것 같습니다.
이런 것 때문에 저는 꿈이 고도의 지능을 가진 존재의 전유물로만 생각했었습니다. 물론 실제 동물들이 사람과 동일한 체험을 하는지는 정확히 알 수는 없습니다. 꿈을 꾸었다는 것을 직접 '증언'할 수 있는 것은 '아직은' 사람 밖에 없기 때문이죠. 하지만 앞으로 동물의 뇌파나 행동, 신체반응을 해석할 수 있는 새로운 기술이 나타난다면 그 생각은 달라질 수도 있을 겁니다. 현 시점에서도 사람이 꿈을 꿀 때 나타나는 신체적인 현상(예: 렘수면에서의 안구운동 및 신체활동 변화 등)과 동물의 그것을 비교 연구한 과학자들에 따르면 ' 동물도 꿈을 꿀 수 있을 것이다'란 쪽으로 생각이 전환되고 있는 것 같습니다. 그래서 저도 최근엔 생각을 바꿨구요. ( 링크)
내년에는 잠잘 때의 '꿈'도, 목표로 하는 '꿈'도 둘 다 기억에 오래 남기고 그리고 '드디어 이뤘어' 라는 말을 할 수 있기를 기원합니다.
|
|
|
2023년의 마지막 주를 맞아 연초에 한해동안 하겠다고 마음먹은 것들을 얼마나 이루었는지 돌아보면 늘 그렇듯 아쉬움이 남습니다. 다소 도전적인 목표를 잡았던 것도, 전반적인 주변 상황이 녹녹치 않았던 것도 다 원인이 될 수 있겠지만 가장 큰 것은 '중꺽마(중요한 것은 꺽이지 않는 마음)' 정신이 부족했기 때문인 것 같습니다. 아주 작은 것이라도 지속적으로 성공하는 경험을 하는 것이 중요한데 잦은 포기로 거꾸로 실패하는 경험을 늘려간 것 같다는 거죠. 내년에는 그러지 말자 하며 다시 마음을 다잡아 봅니다. 2024년 전망이 국내,국외 상황을 보면 상당히 불투명해 보이긴 합니다. 하지만 기저효과 때문에라도 내년은 올해보단 낫겠지 하는 기대를 해 봅니다. 간절한 희망을 듬뿍 담아서 말입니다. |
|
|
사진: 영화 중경삼림의 두번째 에피소드 중 한 장면 (출처) |
|
|
덧없이 빨리 흘러가는 시간을 생각하다보니 영화 중경삼림 두번째 에피소드의 한 장면이 떠올랐습니다. 주인공인 경찰 663 (양조위)과 페이(왕페이)의 가게 씬인데. 두 사람의 움직임은 아주 느리게, 지나가는 주변 사람들의 움직임은 아주 빠르게 대비함으로써 인물이 느끼는 심리적 시간을 보는 사람으로 하여금 알게 해 주는 효과를 주었죠. 그런데 왜 그 장면이 떠 올랐냐구요? 실제 영화 내용과는 무관하게, 빠르게 지나가는 시간 속에서 큰 발전없이 정체되고 있다는 위기감을 느끼는 제가 그 속에 있는 것 같다는 생각 때문이었습니다. 아이러니하게도 영화 속 장면은 스텝프린팅 기법 (피사체를 저속 촬영 후 다른 원본 영상 프레임에 붙여 넣는 기법) 대신 양조위 본인이 실제로 슬로우 모션 연기를 하는 방식으로 찍었다고 합니다.
아무쪼록 행복한 연말연시 보내시고 다가오는 2024년 새해에는 복 많이 받으시기 바랍니다.
소이뉴스는 내년에도 열심히 새로운 소식을 전하기 위해 노력하겠습니다. |
|
|
특허청, LG AI연구원과 초거대 특허전용 언어모델 개발
특허청과 LG AI연구원이 특허 관련 업무 혁신을 위해 초거대 특허전용 언어모델을 구축했다고 밝혔습니다. LG의 LLM인 EXAONE으로 특허청이 가지고 있는 특허행정과 관련된 7종의 정보를 학습해서 구축됐다고 하며 이번에 개발된 언어모델을 기반으로 내년부터 특허검색, 분류 등 심사업무 쪽 혁신을 위해 추가적인 연구개발이 이뤄질 것이라고 합니다. ( 기사)
|
|
|
국민연금공단, AI사원 2명 임용
민간이 아닌 공공기관에서도 이제 AI 직원 채용이 이뤄지고 있습니다. 이번에 채용된 AI사원은 실시간으로 10개 국어 통역 서비스를 통해 외국인 가입자들을 응대할 수 있고 온라인 홍보 및 교육 컨텐츠 등에서도 활약할 것이라고 합니다. 재미난 것은 남여 한쌍인 AI사원 정드림 주임과 국연아 주임은 공단 직원 100명의 사진을 합성해서 만들어졌다는 것입니다. ( 기사) 예전에 봤었던 'Average Face'( 링크)에서 사람들의 얼굴을 평균하면 훨씬 더 매력적으로 보인다는 내용이 있었는데 그 효과를 노린 것이 아닌가 생각해 봅니다. |
|
|
농총진흥청, 노지 스마트농업 시범지구 전국 9개 시군 지정
농촌진흥청이 2024년부터 3년간 전국의 주요 노지작물 주산지 9곳과 '노지 스마트농업 시범지구'를 조성해 인공지능, 빅데이터, 로봇, 감지기(센서) 등 첨단기술을 노지에 적용하기로 업무 협약을 체결했습니다. 노지작물 주산지 9곳은 함양군(양파), 당진시(벼), 거창군(사과), 옥천군(복숭아), 상주시(포도), 연천군(콩), 김제시(밀·콩), 신안군(대파), 평창군(배추·무) 등입니다. ( 기사) |
|
|
사진: 노지 스마트농업 시범지구 조성,운영 업무협약식 (출처) |
|
|
뉴욕타임즈, Microsoft와 OpenAI를 저작권 침해 혐의로 고소
미국의 대표적인 언론사인 뉴욕 타임즈가 마이크로소프트와 OpenAI를 저작권 침해 혐의로 고소했습니다. 자사의 기사 데이터를 ChatGPT 등 AI 학습을 위해 무단으로 사용했다는 것이죠. 초거대 언어모델을 개발하기 위해서는 방대한 자료들이 필요하고 그 가운데 비단 이번처럼 언론사 기사 외에도 인터넷 상에 퍼져 있는 수많은 정보들을 사용되는데 그것들 중 일부는 이번처럼 저작권과 관련된 문제를 일으킬 수 있는 것들이 포함될 가능성이 높습니다. 이번 소송은 한 언론사와 빅테크 간의 금전적인 보상 문제라기 보다는 앞으로 AI의 발전을 위해 사회가 어느 수준까지 용인할 것이냐 그리고 그것으로 인해 AI의 발전 속도가 꺾일 것인지 아닌지를 판가름하는 기준을 마련할 것이라는 점에서 중요한 사건이라 생각됩니다. ( 기사) |
|
|
업스테이지, 자체 개발 LLM 'Solar' 공개
국내 AI스타트업인 업스테이지에서 오픈소스 기반 초거대언어모델인 ' Solar'를 공개했습니다. 현재 Solar는 HuggingFace 의 Open LLM Leaderboard에서 평가점수 74.2로 최상위권을 차지하고 있습니다. 총 107억개(10.7B)개의 매개변수를 가진 모델인데 그 보다 큰 모델들보다 좋은 성능을 보여주고 있습니다. 매번 해외의 새로운 모델들을 소개하다보니 한국에서 개발한 모델이 1등을 차지하면 괜히 기분이 좋아집니다. ( 기사) |
|
|
사진: HuggingFace의 Open LLM Leader 보드 순 (출처) |
|
|
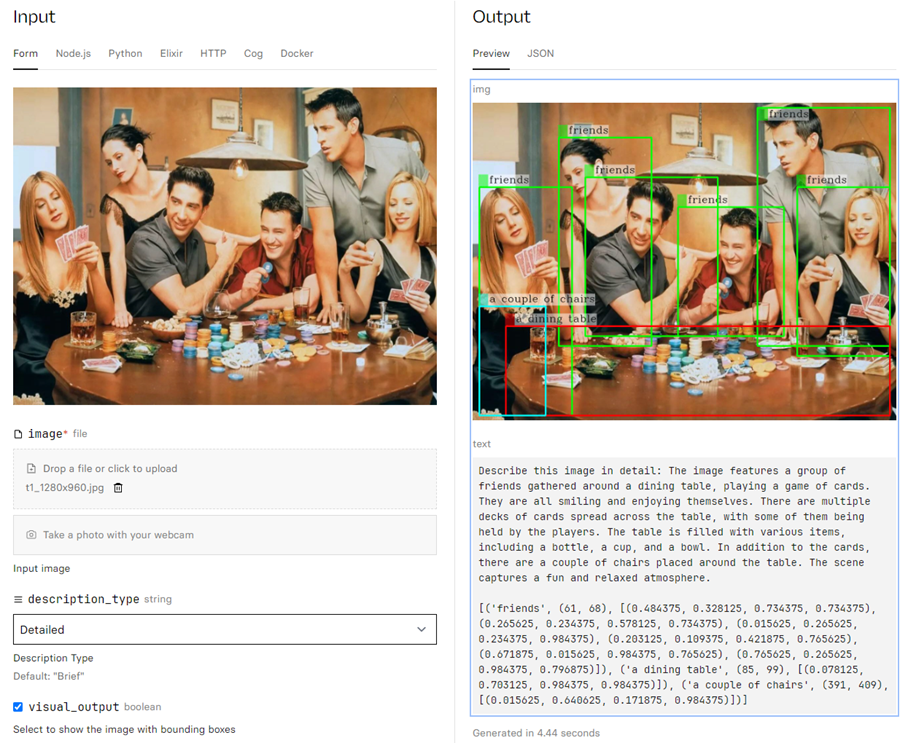
Kosmos-2는 Microsoft가 공개한 다중모드 대형 언어모델 (MLLM)입니다. MLLM은 텍스트 외에도 다양한 양식과의 상호작용을 하기 위한 것인데 결국 사람과 AI가 상호 작용하는 방식을 혁신하는데 목표를 두고 있다고 보면 되겠습니다. 이런 역할을 하는 다른 모델로는 Grounding DINO가 있죠. 이 모델이 제공하는 기능으로는 이미지 인식, 물체 설명, 물체 갯수 세기, 이미지에서 텍스트 읽기, 이미지 간의 차이점 식별, 세부 이미지 설명 등이 있습니다. 미디엄 등에는 이 모델을 이용한 다양한 예제들이 올라오고 있으니 참고하시기 바랍니다. 앞으로 이런 모델들이 좀 더 정교화, 고도화되면 이미지 데이터에 대한 데이터 가공 작업은, 가이드 프롬프트만 잘 제공되면 아주 쉽고 빠르게 처리할 수 있지 않을까 싶습니다.
참고로 Kosmos-2와 GriT-20M이라는 데이터셋이 공개되었는데 이는 COYO-700M 및 LAION-2B 하위 집합의 이미지-텍스트 쌍을 기반으로 생성되었다고 합니다.
|
|
|
사진 : KOSMOS-2 데모에서 Friends 한 장면을 이용한 실행 예제 (참조) |
|
|
InstructVideo : Instructing Video Diffusion Models with Human Feedback
|
|
|
InstructVideo는 인간의 피드백을 반영하여 Text to Video 확산 모델을 파인튜닝하는 기법으로 인간 선호도에 최적화된 비디오를 생성하면서도 동시에 일반화 능력도 유지할 수 있다는 장점이 있습니다. Text to Video 확산모델인 ModelScopeT2V를 기본모델로 하고 인간 피드백을 반영하여 비디오의 시각적 품질을 향상시키는데 이때 인간 선호도 데이터셋 제작 대신 기존의 이미지 보상 모델(HPSv2)을 활용하는 방식을 채택하고 있습니다. 또한 전체 DDIM 샘플링 체인을 통해 비디오를 생성하지 않고 샘플링된 비디오를 확산 과정을 통해 변형하여 파인튜닝의 비용과 효율을 개선하며 파인튜닝 도중에 시간적 모델링의 성능 저하를 완화하기 위해 보상 신호에 시간적 감쇠를 적용한다고 합니다.
* 실행 코드는 곧 공개될 예정이라고 합니다. |
|
|
사진: InstructVideo framework 개요 (상), 모델의 reward fine-tuning framework (하) (출처) |
|
|
GLEE : General Object Foundation Model for Images and Videos at Scale
|
|
|
GLEE는 이미지와 비디오를 위한 객체 수준의 기본 모델로, 객체감지, 인스턴스 분할, 그라운딩, 다중 타겟 추적, 비디오 인스턴스 분할, 비디오 객체 분할, 인터랙티브 분할 및 추적 등 다양한 수준의 이미지, 비디오 작업을 동시에 수행할 수 있습니다. 게다가 다양한 벤치마크에서 얻은 500만 개 이상의 이미지 데이터를 가지고 학습되어 그 자체로도 높은 성능을 보이며 최신 LLM에서 부족한 시각적 개체 수준 정보를 제공하기 위한 기본 컴포넌트 역할로도 활용할 수 있습니다.
GLEE는 텍스트 인코더, 이미지 백본(인코더), 비주얼 프롬프터, 객체 디코로 구성되며 각각 다음과 같은 역할을 수행합니다.
- 텍스트 인코더(Text Encoder)
개체 범주(category), 모든 형식의 이름(arbitrary name), 개체에 대한 캡션(object caption) 및 참조 표현(expression)을 포함하여 작업과 관련된 임의의 설명 처리
- 이미지 인코더 (Image Backbone)
- 시각적 프롬프터 (Visual Prompter)
대화형 분할 중에 포인트, 바운딩 박스 또는 낙서(예:사용자의 그리기 입력) 같은 사용자 입력을 대상 개체의 해당 시각적 표현으로 인코딩
- 객체 디코더(Object Decoder)
앞서 나온 입력값들과 이미지 특징을 이용해서 이미지 상에서의 객체 감지 수행
|
|
|
인공지능 서비스의 배포와 운영 시 도움이 필요하신가요?
(주)소이넷은 인공지능 서비스를 제공하는 기업들 가운데 서비스 배포와 운영에서 어려움을 겪고 계신 곳에 도움을 드릴 수 있습니다.
혹시 구독자님의 회사는 다음과 같은 어려움을 겪고 계시지 않나요?
- AI 모델을 개발하고 학습 후 서비스를 위한 성능(Accuracy)은 달성했는데, 정작 최적화 엔지니어가 없어서 어플리케이션, 서비스로의 배포를 위한 실행최적화를 못하고 있어요!
- AI 서비스를 이미 제공하고 있지만, 비싼 클라우드 GPU 서버 인스턴스 사용료가 부담이 되네요. 흠... 경비를 절감할 수 있는 방안이 없을까?
- 서비스에 적합한 공개 SOTA 모델이 있지만 그대로 가져다 쓰기에는 우리 쪽 어플리케이션에 접목하기도 어렵고 운영 비용도 많이 들 것 같은데 어쩌지?
- 서비스에 사용되는 AI 모델을 통합적으로 관리, 배포, 모니터링을 하고 싶은데 그렇다고 비싸고 너무 복잡한 솔루션을 쓸 수는 없고 어쩌지?
- 비즈니스 도메인 기업이긴 한데 자체로 인공지능을 적용하기에는 기술적인 난이도도 있고... 어디 함께 공동 솔루션을 개발할 곳은 없을까?
그렇다면 언제든 아래 연락처로 문의 주세요. 함께 해결책을 고민해 드리겠습니다.
|
|
|
오늘의 뉴스레터는 여기까지
구독자님,
다음 번에도 재미나고 흥미로운 소식을 가지고
다시 찾아뵙겠습니다. |
|
|
구독해 주시면 좋은 소식, 정보로 보답하겠습니다. |
|
|
주식회사 소이넷
sales@soynet.io
경기 성남시 분당구 성남대로331번길 8 (킨스타워) 1503호
대표전화 : 031-8039-5377
|
|
|
|
|