새롭고 흥미로운 인공지능 기술을 소개합니다. 안녕하세요, 구독자님.
이번 한 주도 잘 보내고 계신가요?
최근에 저를 놀라게 한 뉴스가 몇 가지 있었습니다. 아시는 분들도 많으실텐데요...
우선 지난 주말(24일)에는 우크라이나-러시아 전쟁 중에 와그너라는 러시아 용병그룹의 반란 사태가 있었는데 짧았지만 예상치 못했던 상황이라 전세계적가 다 긴장하며 사태 추이를 지켜봤었습니다. 결국은 수도인 모스크바 200km 전까지 진군했다가 와그너를 이끄는 수장 프리고진은 벨라루스로 망명하고 나머지는 다시 러시아 정규군에 편입되었다고 하죠. 아직은 이후 진행이 어떻게 될지 불투명한 상태인 것 같습니다.
또 하나의 예상치 못했던 소식은 미국 쪽에서 나왔습니다. 다소 뜬금 없어 보이는데요... 테슬라 CEO 일론 머스크와 META CEO 저커버그 간의 결투 ('현피'라고들 하죠...) 예고 소식이 있었습니다. 세계적인 기업의 수장들이 직접 만나서 케이지 안에서 직접 맞짱을 뜬다는거죠. 설마... 했는데 뒤에 나온 얘기들이 점점 성사 가능성을 높이고 있는 상황입니다. 이종격투기 업계에서는 이미 1조가 넘는 경제효과까지 언급하고 있다죠. 개인적으론 라스베가스 특설링에서 치고받는 것 말고 초거대 기업 수장들끼리 앞으로 기술 쪽이 어떻게 나아갈 것인지 진지한 토론 한번 하고 치고받는 것 없이 대련 형식의 주짓수 대결 한번으로 마무리 하는 것이 좋지 않을까 싶습니다. 그렇지 않고 폭력적인 모습으로 끝난다면 업계나 양사 비즈니스, 주주 등에 다 악영향을 줄테니까요. 하지만, 만약, 만약에라도 하게 된다면... 꼭 지켜보긴 할 겁니다. ^^;
이번 소식에서도 새로 소개된 혹은 이전에 소개되었지만 주목을 끌지 못했던 것 중에 재미난 인공지능 기술 몇 가지를 가져와 봤습니다. |
|
|
Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning |
|
|
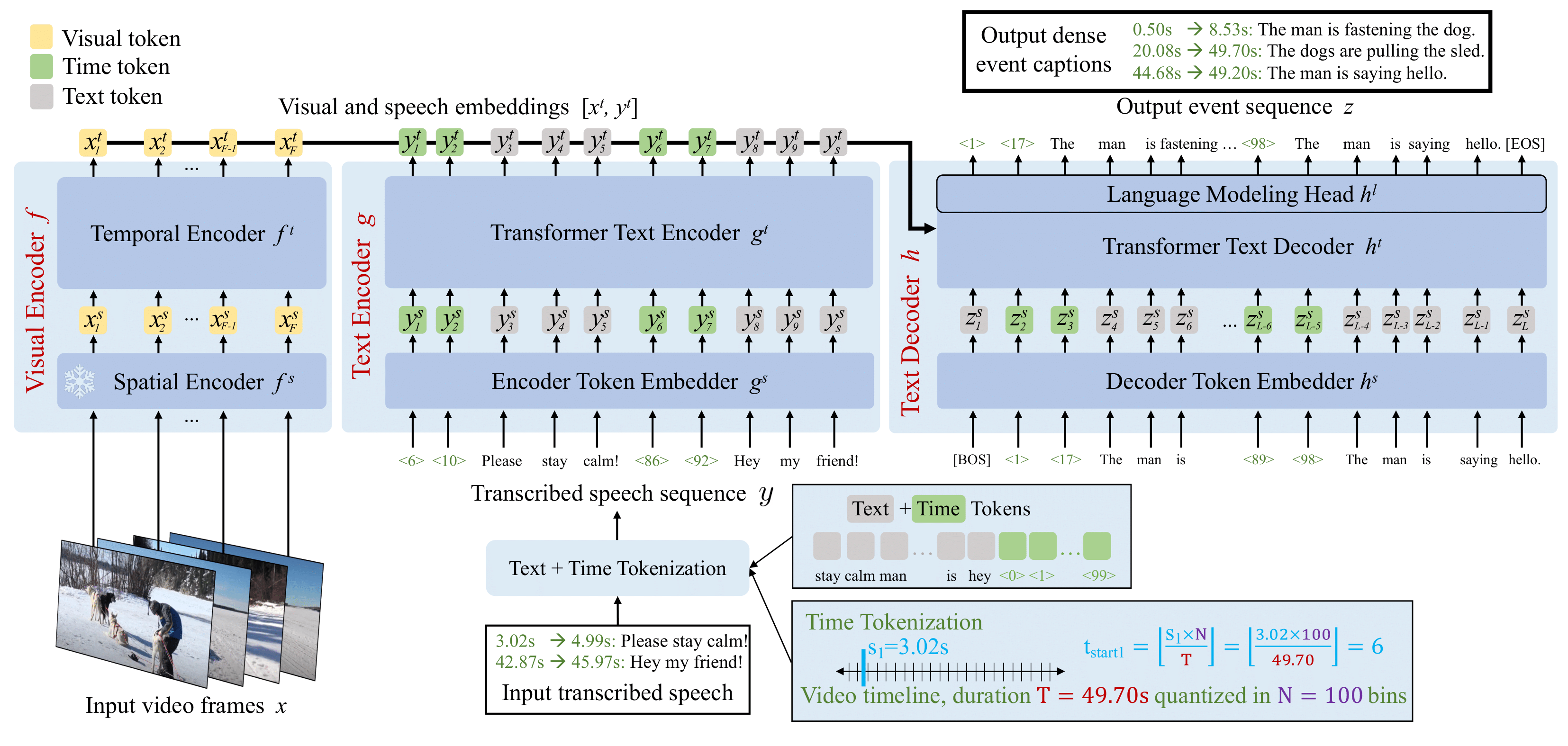
Vid2Seq는 구글에서 발표한 모델로 비디오에서의 영상과 음성을 분석해서 영상을 설명하는 텍스트를 생성합니다. 예를 들어 어떤 비디오 영상을 볼 때 어떤 내용인지를 알기 위해서는 전체 영상을 빠르게 다 돌려봐야 하고 나오는 음성 내용 또한 다 듣고 어떤 내용인지 확인까지 해야 합니다. 긴 영상에서 일정 부분만 중요한 내용이 있고 나머지 긴 시간동안은 동일한 내용의 영상이라면 분석에 소요되는 시간이 다소 아까울 수도 있을 것 같습니다. 이럴 때 Vid2Seq 모델을 이용하면 영상의 몇 프레임에서 몇 프레임까지 어떤 내용이 있다는 설명들을 얻을 수 있게 되어 영상에 대한 이해와 요약을 하는데 큰 도움이 됩니다. Vid2Seq가 이벤트 경계 및 캡션을 하나의 토큰 시퀀스로 동시에 예측하는 장점이 있기 때문이죠. 이 모델은 비디오에 대한 캡션, 요약, 검색, 내용 번역 등을 위해 활용될 수 있습니다.
용어설명) 고밀도 비디오 캡션 : 입력 비디오로부터 이벤트 구간들을 찾아내어 해당 구간의 장면을 설명하는 텍스트 문장을 생성하는 것 |
|
|
사진) Vid2Seq 모델 처리 흐름 (상)과 처리 결과물(하) (출처) |
|
|
MagicPony: Learning Articulated 3D Animals in the Wild |
|
|
MagicPony는 Visual Geometry Group과 옥스포드 대학 연구팀이 공동으로 발표한 모델로 입력된 단일 이미지 상의 말(horse)의 형상을 이용해서 3D 형상으로 재구성하고 이를 원하는 시점에 맞춰 렌더링하는 기능을 제공합니다. 이는 대상이 되는 물체(동물)의 형태와 움직임을 정확히 예측할 수 있기 때문이죠. 게다가 미세조정을 할 경우, 다른 동물에 대해서도 적용이 가능하다고 하네요. 실제 사진을 이용해서 학습을 했음에도 불구하고 추상적인 이미지 (예: 그림) 등에도 적용이 가능하다는 특징이 있습니다. 응용해서 써먹을 분야가 많겠습니다.
|
|
|
사진) MagicPony 모델의 학습 파이프라인 (상)과 실행 결과물 (하) (출처) |
|
|
Word-level timestamps with Whisper |
|
|
OpenAI에서 발표했던 다국어 인식 모델인 Whisper는 이미 알고 계시리라 생각합니다. 무려 100개 (발표 이후 계속 수는 늘고 있습니다) 이상의 전세계 언어를 인식하고 번역할 수 있죠. 저도 공개된 코드를 이용해서 STT (Speech To Text) 응용 데모를 만들어 보기도 했는데요... 결과물의 품질은 인상적일 정도로 괜찮았습니다.
최근 Whishper를 이용해서 단어 단위로 timestamp를 추출하려는 시도들이 있었습니다. WhisperX 나 whisper-timestamped 같은 것들이 그런 예죠. 예전 기억을 떠 올려 보면, 2000년대 초였던가... MagicEnglish라는 Text to Speech 방식으로 음성합성 기술을 이용해서 영어 공부를 할 수 있는 PC용 프로그램이 있었습니다. 당연히 지금과 같은 인공지능을 사용한 것은 아니었을테죠. 입력된 텍스트를 영어로 읽어주면서 화면 상에 해당 단어들을 하이라이트 시켜주는 기능이 있었는데 그 장면들이 생각났습니다. 모양새는 비슷하거든요. 합성한 음성에 해당하는 단어를 표시만 하던 것이 기존 어플리케이션이었다고 하면 지금 소개하는 기능은 실제 비디오 영상 혹은 음성에서 추출한 정보를 이용해서 표시해 준다는 점에서 다르다고 할 수 있겠습니다. 유튜브 실시간 영상에서 화자의 발화 시 그 부분에 해당하는 자막에 단어 단위로 하이라이트를 제공하는 앱등이 가능하지 않을까 싶네요.누가 한번 링크에 있는 HuggingSpace 데모를 위한 python 코드를 이용해서 로컬에서 구현해 보실 분 없으실까요? ^^;
|
|
|
사진) HuggingSpace 상의 데모에서 mp3 파일 입력으로 나온 실행 결과 (링크) |
|
|
LART (Lagrangian Action Recognition with Tracking)
|
|
|
LART (Lagrangian Action Recognition with Tracking)는 3D 자세예측과 트래킹을 이용해서 행동인식을 하는 모델입니다. 이를 이용하면 영상에서의 사람이 뛰거나 쓰러지거나 춤은 춘다거나 하는 행동등을 각 사람 개체 별로 판별할 수 있게 됩니다. 이 모델이 기존의 모델과 좀 다른 것은, 행동을 하는 사람의 3D 자세와 트래킹을 함께 사용한다는 것이고 그 결과 기존 모델들 대비 훨씬 높은 성능을 달성했다는 것입니다. 인간의 행동 인식은 워낙 사용되는 곳이 많아서 해당 모델을 잘 응용하면 다양한 영역에 활용할 수 있습니다. 예를 들어 이상행동 감지가 필요한 곳에서의 CCTV 영상 분석같은 곳 말이죠.
|
|
|
사진) LART 모델 개요(상)과 결과 예시(하) (출처) |
|
|
인공지능 서비스의 배포와 운영 시 도움이 필요하신가요?
(주)소이넷은 인공지능 서비스를 제공하는 기업들 가운데 서비스 배포와 운영에서 어려움을 겪고 계신 곳에 도움을 드릴 수 있습니다.
혹시 구독자님의 회사는 다음과 같은 어려움을 겪고 계시지 않나요?
- AI 모델을 개발하고 학습 후 서비스를 위한 성능(Accuracy)은 달성했는데, 정작 최적화 엔지니어가 없어서 어플리케이션, 서비스로의 배포를 위한 실행최적화를 못하고 있어요!
- AI 서비스를 이미 제공하고 있지만, 비싼 클라우드 GPU 서버 인스턴스 사용료가 부담이 되네요. 흠... 경비를 절감할 수 있는 방안이 없을까?
- 서비스에 적합한 공개 SOTA 모델이 있지만 그대로 가져다 쓰기에는 우리 쪽 어플리케이션에 접목하기도 어렵고 운영 비용도 많이 들 것 같은데 어쩌지?
- 서비스에 사용되는 AI 모델을 통합적으로 관리, 배포, 모니터링을 하고 싶은데 그렇다고 비싸고 너무 복잡한 솔루션을 쓸 수는 없고 어쩌지?
- 비즈니스 도메인 기업이긴 한데 자체로 인공지능을 적용하기에는 기술적인 난이도도 있고... 어디 함께 공동 솔루션을 개발할 곳은 없을까?
그렇다면 언제든 아래 연락처로 문의 주세요. 함께 해결책을 고민해 드리겠습니다.
|
|
|
오늘의 뉴스레터는 여기까지
구독자님,
다음 번에도 흥미로운 소식으로
다시 찾아뵙겠습니다. |
|
|
구독해 주시면 좋은 소식, 정보로 보답하겠습니다. |
|
|
주식회사 소이넷
sales@soynet.io
경기 성남시 분당구 성남대로331번길 8 (킨스타워) 1503호
대표전화 : 031-8039-5377
|
|
|
|
|