출산율 급감이 가져올 미래에 대한 우려 안녕하세요, 구독자님.
즐거운 한 주 보내고 계신가요?
이번 주부터 학생들이 긴 여름방학을 마치고 새로운 학년을 시작했습니다. 초등학교 앞을 지날 때면 아이들의 재잘거림을 들으며 알게 모르게 어린 시절이 떠올라 무선충전 하듯 에너지를 얻기도 했습니다. 그런데... 앞으로는 이런 모습을 보기가 점점 더 힘들어질지도 모르겠습니다.
최근 통계청에서 2023년 합계출산율(*)을 발표했습니다. 0.72! 기억하실 지 모르겠지만 작년 말 EBS 다큐멘터리에서 미국 교수님 한분이 우리나라의 합계출산율이 0.78아라는 것을 듣고 “대한민국 완전히 망했네요. 와!” 하며 놀라셨습니다. (링크) 그분의 리액션 덕분에 한동안 뉴스기사와 블로그들에서 해당 내용은 밈처럼 퍼져나갔었죠. 그런데 이 수치는 작년 4분기만 놓고 보면 0.65라고 합니다. 전쟁 중인 국가에서나 나올만한 수치라는데 어쩌다 이 지경까지 된 것일까요? 실제 우리나라의 합계출산율은 OECD 회원국 뿐만 아니라 전체 국가 순에서도 가장 낮은 수준입니다. 2021년 기준으로 세계 225개국 가운데 꼴찌였던 홍콩이 0.7, 우리나라는 0.88이었는데, 그 이후의 급격한 변화로 보면 아마도 현 시점에서의 '뒤에서 세계 1위'는 우리나라일 것 같습니다. (기사, 블로그)
* 합계출산율 : 여성 1명이 평생 낳을 것으로 예상되는 평균 출생아 수 |
|
|
사진: 한국의 출산율을 들은 외국인 교수님 리액션 (출처) |
|
|
출산율이 아니라 출생아 수치로 보면 2016년 40만명을 웃돌다가 작년에는 23만명으로 8년 정도 만에 거의 절반 수준으로 떨어졌습니다. 최근 뉴스 등에서 대학신입생 수가 급감했다, 군입대자 수가 급감했다, 초등생이 사라진다 등과 같은 얘기를 들어 보셨을 겁니다. 실제 올해 전국 초등학교 6175개 중 2.5%에 해당하는 157개 초등학교에서 신입 1학년 아동이 전혀 없다는 기사가 있었습니다. 한 학년 전체가 없어진건데 이게 이번만의 일이 아니게 되면 몇년이 지나면 아예 학교 자체가 없어지게 됩니다. 물론 단순히 출생아 수가 줄어든 것 외에, 도시집중화로 인한 지방소멸과 같은 원인도 함께 관련되어 있겠죠. 이렇게 출생아 수가 줄어드는 추세 자체보다는 진행이 너무 급격하게 된다는 것과 결과적으로 우리가 가보지 않은 길로 우리가 들어서고 있다는 것 때문에 앞으로 야기될 많은 혼란이 우려되는 부분입니다.
도대체 무엇이 이런 현상을 만들고 있을까? 인터넷, 유튜브 상에서는 다양한 현상 해석과 이를 어떻게 대처해야 할 지 방안을 제시하는 분들이 많이 있습니다. 현재 벌어지고 있는 저출생 현상과 한국인들이 갖는 저출생의 문화심리적 이유에 대해 설명하는 분들도 있습니다. (1부, 2부) 단순하게 소득과 주택 등의 문제로 볼 것이 아니라 노동시간 단축, 성차별적 문화 개선(임금격차, 유리천장(*), 경력단절), 거주문제 해결, 결혼에 대한 인식 변화 등 다양한 해결책을 함께 적용해야 하는 복합 문제라는 얘기를 하고 있죠. 나름 그 분야에서 오랫동안 연구나 고민을 해 오신 분들이시니 근거가 없진 않을테고 어떤 것들은 실생활에서 효과를 거둔 사례도 있는데 왜 근본적 해결은 요원한 것일까요?
*유리천장 : 충분한 능력을 갖춘 사람이 직장 내 성 차별이나 인종 차별 등의 이유로 고위직을 맡지 못하는 상황. 이를 수치화한 것을 유리천장지수(Glass Ceiling Index)라고 함 (관련기사)
양자역학이 다루는 미시세계에서는, 전자를 관찰하려는 바로 그 행위 때문에 아이러니하게도 정확한 위치 파악이 불가능하다는 얘기가 있습니다. 적절한 비유가 아닐 것 같긴 합니다만... 하나의 문제를 해결하기 위해 어딘가를 건드리면 다른 곳에서 예상치 못한 현상이 나타나 다시 문제가 반복되는 그런 현상이 우리사회에는 너무 많은 것 같습니다. 한마디로 제대로 관찰하고 제대로 해석하는 것도 어렵지만 그것에 대한 대안을 내고 직접 적용해서 효과를 거두는 것은 더 어렵다는 것이죠. 사람들 각자의 이해득실이나 관점이 서로 충돌하는 부분들이 있고 이것들이 조율하기에는 극단적으로 어려운 일이기 때문일 겁니다. 예전에 해결해야 하는 문제가 생기면 모여서 함께 논의하는 인디언 아이들 얘기를 한 적이 있었습니다. 지금은 우리가 그래야 하는 타이밍 같습니다. 편가르고 싸우는 것보다는 어떻게든 문제를 해결하려고 합심 노력해야 하는 그런 타이밍 말입니다! 출산율 얘기를 하다가 엉뚱하게 여기까지 왔네요...
시기 상으로 본격적인 봄으로 가는 길목입니다. 아무쪼록 행복한 오후, 주말 보내시기 바랍니다. |
|
|
KAIST 연구진, LLM 처리 가능한 AI반도체 '상보형-트랜스포머' 개발
KAIST 연구팀에서 초저전력으로 LLM을 구현할 수 있는 AI 반도체 '상보형-트랜스포머'(Complementary-Transformer)를 삼성28나노 공정으로 개발했다고 밝혔습니다. LLM은 학습이 아닌 추론만 하더라도 고성능의 GPU를 필요로 하는 것이 일반적입니다. 이번에 개발된 AI반도체 칩은 4.5mm x 4.5mm 크기의 작은 칩 하나에서 이를 동작할 수 있도록 한 것이라는데 정말 놀랍습니다. DNN-to-SNN 등가변환기법을 통해 성능은 보존하면서, 파라미터 압축기법을 통해 외부 메모리 접근을 줄이면서 경량화와 속도를 함께 잡은 것도 대단합니다.
'상보형'라는 용어는 SNN(스파이킹 뉴럴 네트워크)와 DNN(심층신경망)이라는 2개의 신경망을 선택적으로 사용해서 네트워크를 만든다는 것으로 입력 데이터의 크기에 따라 서로 다른 신경망을 할당하는 방식인 것 같습니다. ( 기사, 보도) |
|
|
Stability AI, Stable Diffusion 3 출시
Stability AI가 오픈소스 이미지 생성모델인 Stabile Diffusion 3 모델을 공개했습니다. 이번에 공개된 모델에서는 최근 소개된 Diffusion Transformer 아키텍처가 도입되었습니다. 지난 8월 SDXL이 소개되면서 다양한 응용 사례가 나왔었는데 이번 버전은 그보다 성능이 훨씬 나아졌다고 합니다. 이 모델의 기능을 확장해 3D 모델이나 OpenAI의 Sora처럼 비디오를 생성하는 모델로 발전시키는 사례도 향후에 나올 수 있지 않을까 예상됩니다. ( 기사) |
|
|
Anthropic, Claude-3 출시
OpenAI의 경쟁자 중 하나인 Anthropic이 멀티 모달 모델 Claude-3를 출시했습니다. 이번에 발표한 것은 경량모델인 Haiku 부터 그보다 더 규모가 큰 Sonnet, Opus까지 3개의 모델을 발표했는데 이 가운데 Opus의 경우는 이 분야 기존 최강자인 GPT-4와 Gemini Ultra의 성능을 뛰어넘는다고 발표되었습니다. 그동안 많은 LLM들이 발표되었지만 정작 GPT-4는 넘사벽처럼 언급되어 왔는데 최근에는 '한번 겨뤄 볼까?' 하는 수준의 모델들이 하나둘씩 나오고 있는 것 같습니다. 또 모르죠... OpenAI가 바로 이 때쯤 GPT-5 같은 것을 내놓으면서 '어림없어!'하며 멀찍이 도망갈지도 말이죠. 하지만, OpenAI나 구글도 이제는 잔뜩 긴장해야 하는 시간이 온 것 같긴 합니다. ( 블로그) |
|
|
사진: Claude-3 모델의 성능 비교 (출처) |
|
|
Stability AI와 Tripo AI가 제휴를 통해 TripoSR이라는 고품질 3D 모델 생성도구를 공개 했습니다. LRM(Large Reconstruction Model)의 원리를 활용해서 3D 재구성 속도와 품질을 향상시킨 것이 기존의 다른 유사 모델 대비 가지는 차별점인 것 같습니다. GPU 외에 CPU에서도 구동 가능하며, 고품질의 3D 모델을 0.5초 (A100 기준) 이내에 만들어 낼 수 있다고 하니 자랑할만하네요. ^^;
제공되는 데모를 이용하면 2D 사진을 입력으로 하면 3D로 모델을 생성해 특정 포맷(obj)으로 다운로드도 가능합니다. 그렇다는 얘기는 obj를 stl로 변환해서 3D 프린터로 출력도 가능하다는 말이 되겠죠? 한번 시도해 봐야겠습니다. : ) 또 어떤 분은 Apple의 Vision Pro 상엔서 Midjourney로 이미지를 생성하고 TripoSR로 모델을 만들고 이를 다시 USDZ(AR용 3D 파일 포맷)으로 변환하는 방식으로 작업하는 영상을 공개하기도 했고, 또 다른 분은 Midjourney → TripoSR → MeshLab → Mixamo → Reality Converter 의 과정을 거친 AR 생성 예제 영상을 올려두었습니다.
|
|
|
사진: 타 모델들과의 3D 모델 생성 결과 (상) 및 성능 (하) 비교 (출처) |
|
|
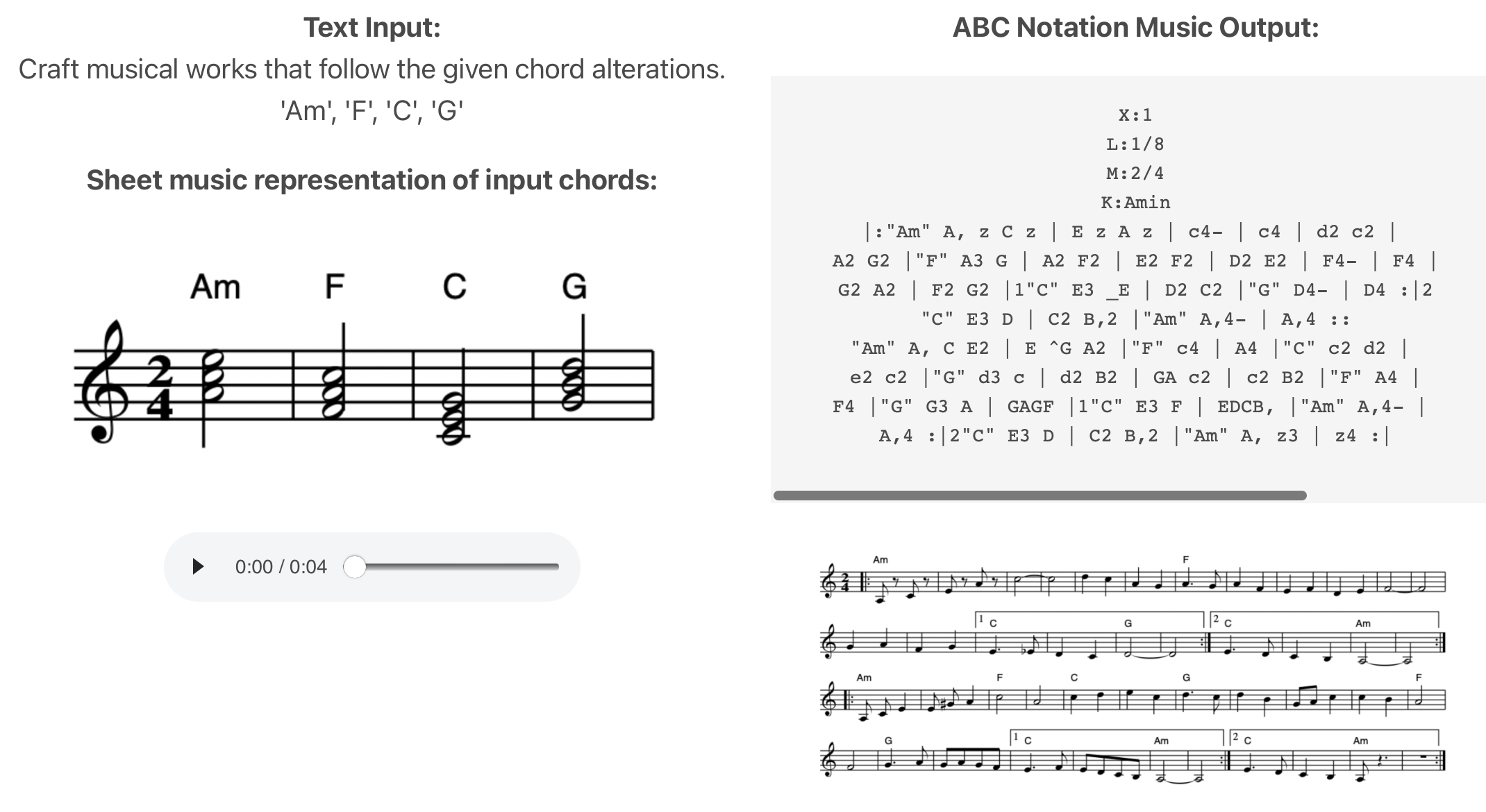
ChatMusician는 음악을 생성하는 오픈소스 LLM 모델입니다. 여기에는 LLaMA2가 적용되어 있으며 음악의 텍스트 호환 음악 표현, ABC 표기법 등을 사전 훈련하고 미세조정을 거쳤습니다. 일반적으로 음악이라고 하면 아... 당연히 멀티모달 방식이겠구나 하실 수도 있는데 ChatMusian의 경우에는 순수하게 텍스트 토크나이저로 음악을 이해하고 생성합니다. 게다가 텍스트, 코드, 멜로디, 모티브, 음악 형식 등을 조건으로 구조화된 음악을 구성할 수 있다고 하네요. 사전 훈련에 사용한 코퍼스 데이터는 MusicPie 것인데, 훈련 데이터 대부분이 아일랜드 음악 스타일이라고 하며 형식도 아직은 엄격히 정의된 형식과 폐쇄형 지침만 지원되는 제약 사항이 있다고 합니다.
공개된 코드를 이용하면 Gradio를 이용해 직접 테스트해 볼 수도 있습니다.
|
|
|
사진: ChatMusician 개요 (상), 실행 결과 예시 (하) |
|
|
SMPLer-X은 인간의 신체 (몸, 손, 얼굴 등)의 모양과 동작을 실제와 유사하게 재현하도록 만들어주는 모델로 사진이나 비디오에서 관찰된 사람의 포즈와 형태를 정확하게 추정하는 것을 목표로 합니다. 이 모델은 3D 신체 모델링을 위한 SMPL 모델을 확장한 것으로, 백본(backbone)은 ViT(Vision Transformer)을 이용해 이미지 특징을 추출하고, Neck은 특징맵에서 손과 얼굴의 바운딩 박스와 자르기 관심 영역 예측하며, Head(Regression Head)에서는 각 부분의 매개변수를 추정하도록 구성되어 있습니다.
기존 방식은 한정된 훈련 데이터셋에 의존하므로 이제껏 보지 못했던 시나리오에 일반화하는 것이 어려웠습니다. 이 때문에 EHPS (Expressive human pose and shape estimation) 데이터셋에 대한 체계적이고 포괄적인 벤치마크 구축하고 데이터 및 모델 스케일링을 탐색해서 다양한 시나리오 균형잡힌 결과를 제공하는 기초 모델을 구축하는 작업을 진행했다고 합니다.
|
|
|
사진 : SMPLer-X 모델의 아키텍처 (상), 모델 별 MPE 비교 (하) (출처) |
|
|
인공지능 서비스의 배포와 운영 시 도움이 필요하신가요?
(주)소이넷은 인공지능 서비스를 제공하는 기업들 가운데 서비스 배포와 운영에서 어려움을 겪고 계신 곳에 도움을 드릴 수 있습니다.
혹시 구독자님의 회사는 다음과 같은 어려움을 겪고 계시지 않나요?
- AI 모델을 개발하고 학습 후 서비스를 위한 성능(Accuracy)은 달성했는데, 정작 최적화 엔지니어가 없어서 어플리케이션, 서비스로의 배포를 위한 실행최적화를 못하고 있어요!
- AI 서비스를 이미 제공하고 있지만, 비싼 클라우드 GPU 서버 인스턴스 사용료가 부담이 되네요. 흠... 경비를 절감할 수 있는 방안이 없을까?
- 서비스에 적합한 공개 SOTA 모델이 있지만 그대로 가져다 쓰기에는 우리 쪽 어플리케이션에 접목하기도 어렵고 운영 비용도 많이 들 것 같은데 어쩌지?
- 서비스에 사용되는 AI 모델을 통합적으로 관리, 배포, 모니터링을 하고 싶은데 그렇다고 비싸고 너무 복잡한 솔루션을 쓸 수는 없고 어쩌지?
- 비즈니스 도메인 기업이긴 한데 자체로 인공지능을 적용하기에는 기술적인 난이도도 있고... 어디 함께 공동 솔루션을 개발할 곳은 없을까?
그렇다면 언제든 아래 연락처로 문의 주세요. 함께 해결책을 고민해 드리겠습니다.
|
|
|
오늘의 뉴스레터는 여기까지
구독자님,
다음 번에도 재미나고 흥미로운 소식을 가지고
다시 찾아뵙겠습니다. |
|
|
구독해 주시면 좋은 소식, 정보로 보답하겠습니다. |
|
|
주식회사 소이넷
sales@soynet.io
경기 성남시 분당구 성남대로331번길 8 (킨스타워) 1503호
대표전화 : 031-8039-5377
|
|
|
|
|