즐거운 설 연휴 보내시고 복 많이 받으세요 안녕하세요, 구독자님.
이번 한 주 활기차고 보람차게 보내고 계신가요?
이번 주는 설 연휴가 끼어 있습니다. 아마도 오늘 오후 혹은 내일 아침부터 귀성하시는 분들의 행렬이 고속도로를 가득 채우고 있겠죠?
음력을 기준으로 1월 1일 설날을 쇠는 국가는 대부분 중화권 문화를 가진 아시아 국가들입니다. 아예 공휴일로 지정한 곳으로는 우리나라와 북한을 비롯해 중국, 대만, 인도네시아, 베트남, 홍콩, 마카오, 말레이시아, 싱가포르, 몽골, 필리핀 등 총 12개국라고 합니다. (링크) 중국에서는 ‘춘절(春節)’이라고 해서 일 년 중 가장 큰 명절로 여기며 인도네시아는 '임렉(Imlek)', 싱가폴은 '신년(Chinese new year's day)' 등으로 부르는데 이 명칭에는 '중국'을 뜻하는 단어가 들어 있습니다. 인도네시아의 경우는 중국계가 4% 밖에 되지 않고 대부분이 이슬람교인이라 의아했는데 찾아보니 화교 자본 유치를 위해 적극적으로 정책(유교 정식인정, 공휴일 지정 등)을 편 결과이며그래서 지금은 인도네시아에서도 가장 큰 명절 가운데 하나가 되었다고 합니다. 또, 필리핀은 서양의 영향이 커서 그런지 'Lunar New Year’s Day'로 되어 있죠. 그 외에 베트남은 ‘뗃(tết)’, 몽골은 '차강사르(Tasgaan Sar)' 등으로 각각 부른다고 합니다.
우리나라도 예전에는 설날을 ' 구정(舊正)', '정월(正月) 초하루', '음력설', '민속의 날' 등으로 부르기도 했습니다. 조선말기인 1885년 양력을 채택하게 되면서, 설날이 신정, 구정으로 구별되기 시작했고 1985년에는 '민속의 날'로 명칭이 바뀌었다가 1989년부터 다시 '설날'로 불리게 되었다고 합니다. (기사)
음력으로 새해 첫날인 설날을 부르는 말은 제각각 다르지만 이날을 맞이하는 마음만은 국가를 가리지 않고 다 비슷할 것 같습니다. 고향의 가족을 만날 설렘에 즐거워지는, 그리고, 사랑하는 이들에게 올 한해 건강과 행운을 가져다 줄 무언가를 바라는 그 마음 말이죠.
눈치채셨겠지만... 설날을 맞아 '복' 많이 받으시라고 글머리 사진으로 '행운'을 의미하는 네잎클로버를 올려봤습니다. 찾으셨나요? . 그런데 그거 아시나요? 기본이 3장인 클로버의 잎이 4장, 5장, 이렇게 생기는 이유를? 위키백과에서 찾아보면 일시적 형질변형, 즉 기형이 원인으로 나옵니다. 네잎클로버를 한 번 찾으면 근처에서 또 다른 네잎클로버를 쉽게 찾을 수 있는 것도 그런 이유일 것 같습니다. 또 다른 이유로는 생장점(잎으로 분화 전 줄기 끝)에 상처가 나는 경우, 거기서 조금은 작은 잎이 하나 더 나는 경우가 있는데 이렇게 생길 수도 있다고 합니다. 검색을 해 보면 몽골에서는 네잎클로버가 더 많다거나, 일본의 시게오 오바라라는 분이 개량을 통해 56개 잎을 가진 것이 키워 내기도 했다는 것 등을 찾아볼 수 있습니다. ( 기사) 국내에서도 아예 네잎클로버를 대량으로 재배하는 사업을 하는 곳도 있다죠. ( 영상) 역시 기발한 아이디어를 사업으로 연결시키는 바로 그 순발력, 실행력이 중요한 것 같습니다.
아무쪼록 설 연휴 가족과 즐겁고 복된 시간 보내시기 바랍니다~!
|
|
|
AI가 내 CT사진 함부로 못 쓰게…비정형데이터 처리 기준 발표
개인정보보호위원회에서 AI학습용 비정형데이터(이미지, 영상, 음성, 텍스트 등)에 포함된 개인정보의 가명처리 기준을 새롭게 발표했습니다. 개정된 가이드라인에 따르면 개인정보 위험을 사전 확인 및 통제하기 위한 원칙과, 다양한 사례 제공을 통해 현장에서 쉽게 활용할 수 있도록 했다고 합니다.
기술 발전에 따라 비정형 데이터를 이용해 개인식별을 할 수 있는 가능성이 높아지는 상황 때문에 이에 대한 가이드라인 개정이 이뤄진 것으로 볼 수 있습니다. 다만, 비정형 데이터의 속성 때문에 식별 위험성을 명확히 규정하기 어려운 것도 사실입니다. 그래서, 가이드라인에서는 개인식별 위험성 검토 체크리스트를 통해 사전 진단하고, 그래도 발생할 수 있는 위험에 대해서는 관리,환경적 통제방안를 마련하거나 기술적 한계를 보완하는 조치를 권고하고 있습니다. ( 기사) |
|
|
HuggingFace, OpenAI의 GPTs 대항마 Assistants 서비스 공개
OpenAI가 GPTs를 소개하면서 아... AI 시장의 판도가 또 한번 크게 바뀌겠구나 싶었습니다. 동시에 Closed AI의 대표 기업이 시작했으니 언젠간 오픈소스 진영에서도 비슷한 것을 내놓겠거니 했는데 역시나 이번에 HuggingFace에서 Assistants라는 것을 공개했습니다.
이 서비스를 이용하면 GPTs처럼 특화된 나만의 LLM을 생성할 수 있습니다. 이 서비스의 장점은, HuggingFace에 올라와 있는 오픈소스 모델들(현재는 6개 중에서 선택 가능)을 선택적으로 이용 가능하다는 것과 커뮤니티의 의견을 반영해서 지속적으로 부가 기능들이 추가될 수 있다는 점입니다. 다만, 외부에서 함수 호출형태로 사용하는 것은 아직 지원되지 않는 모양입니다. ( 링크) |
|
|
사진: HuggingFace의 Assistants (출처) |
|
|
Google, Bard에 Gemini Pro 적용
구글이 2월 1일부터 LaMDA, PaLM 모델을 대신 Bard에 Gemini Pro를 적용했다고 밝혔습니다. 기존 대비 추론 및 언어 능력이 향상됐고 이미지 생성을 기능이 추가되었다고 합니다. 생성되는 이미지에는 AI가 생성한 것임을 알 수 있는 워터마크가 포함됩니다. 현재 한국어(^^)를 비롯한 40개 이상의 언어를 지원하며 230개 이상의 국가에서 사용 가능합니다. 답변의 근거를 링크로 확인할 수 있고 이용자의 의견을 반영할 수도 있다고 합니다. 기존에 무료로 ChatGPT의 기능과 이미지 생성을 위해 Bing을 이용하던 분들은 이제 선택지가 하나 더 생긴 셈입니다. ( 링크) 또 다른 소식으로는 곧 Gemini Ultra가 적용된 유로 서비스 'Gemini Advanced'가 출시될 것이라는 얘기도 있습니다. ( 기사) OpenAI와 Google간의 선두 다툼의 양상이 어떻게 될지 궁금해 집니다. 다만 이 분야 기술은 계속 발전 중인터라 한동안은 계속 흥미진진하게 지켜봐야 할 것 같습니다. |
|
|
ColBERT v2는 대규모 텍스트 검색을 위한 모델로 2022년 발표된 ColBERT v1의 후속 버전입니다. IR(Information Retrieval), 즉 질의를 받아 수많은 데이터(문서) 가운데 적절한 것을 찾고 순위를 매겨서 제시해 주는 영역에서 사용되는데 이러한 작업은 많은 공간을 차지하고 검색 결과를 찾는 것도 오래 걸리는 단점이 있습니다. ColBERT v2는 이런 문제를 해결하기 위해 경량화된 후기 상호작용(Lightweight Late Interaction), 지식증류(Knowledge Distillation), 색인 개선, 잔차 압축(Residual Compression) 기법을 사용합니다. 결과적으로 ColBERT v2는 MS MARCO, TREC Deep Learning Passgage Ranking 등의 대표적인 벤치마크에서 SOTA를 달성했고 유사 다른 모델들 대비 훨씬 빠르고 효율적으로 작동합니다.
|
|
|
Yolo-World : Real-Time Open-Vocabulary Object Detection
|
|
|
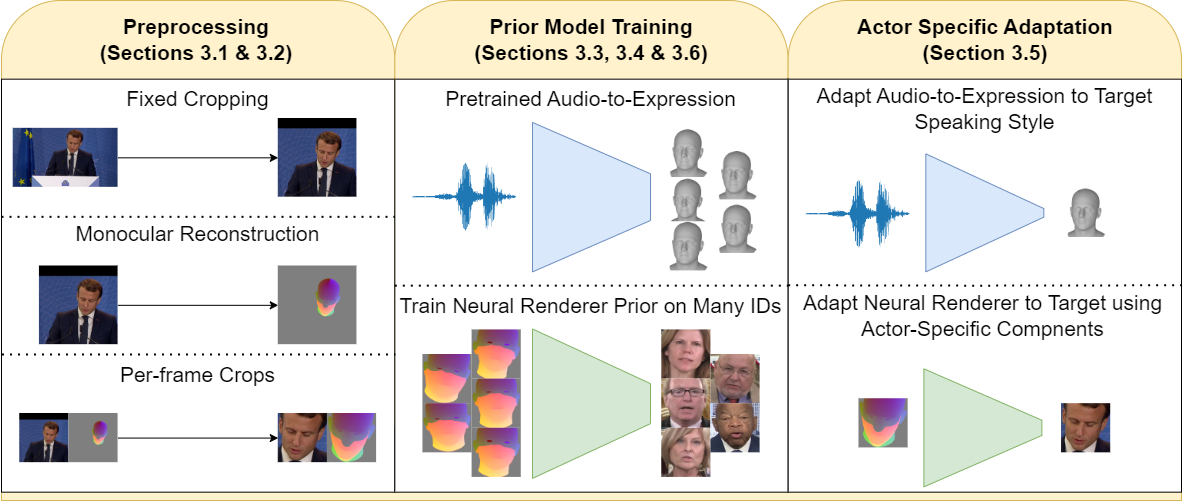
Yolo-World 모델은 2023년에 Facebook AI Research에서 개발한 새로운 실시간 개체 검출 모델로 단일 모델로 시각-언어 모델링과 대규모 데이터셋에서의 사전 학습을 통해 개선하여 다양한 객체를 제로샷 방식으로 정확하게 검출할 수 있습니다.
단일 모델로 3D 객체 인식, 2D 객체 인식, 세분화, 심지어 텍스트 인식 등 다양한 기능을 제공하고 있습니다. 특징으로는 RepVL-PAN(Re-parameterizable Vision-Language Path Aggregation Network)이라는 새로운 네트워크 구조와 영역-텍스트 대조손실(region-text contrastive loss)이라는 목적함수를 이용하고 있습니다. YOLOv8-L을 백본으로 한 Yolo-World-L 모델의 경우, V100 GPU에서 35.4 AP와 52.0 FPS라는 높은 정확도와 속도를 제공합니다.
|
|
|
사진 : Yolo-World 모델 개요 (출처) |
|
|
RAP-SAM:Towards Real-Time All-Purpose Segment Anything
|
|
|
하나의 모델을 이용해 다양한 형태의 분할 또는 세분화(Segmenation)를 지원하는 것으로 지난 번 소식에서 OMG-Seg를 소개해 드린 바 있습니다. RAP-SAM 또한 하나의 모델로 Interactive, Panoptic, video segmentation을 실시간 수준으로 수행할 수 있습니다. 특징으로는 경량화된 특징 추출기, 통합된 디코더, 비대칭 어댑터로 구성되어 분할 작업에 있어 속도와 정확도 둘 다 균형있게 지원한다는 것입니다. 참고로 OMG-Seg의 경우, 비상업적 사용만 가능하도록 제한이 걸려 있었는데 RAP-SAM은 MIT라이선스로 사용에 있어 자유롭습니다.
|
|
|
Motion-I2V는 일관되고 제어 가능한 이미지-비디오 생성을 위한 프레임워크입니다. 일반적으로 이미지나 비디오를 만드는 것을 매우 복잡한 과정을 거칩니다. 이를 단순화하기 위해 Motion-I2V는 이미지나 비디오에서 움직임의 궤적을 예측하는 단계와 시간의 흐름에 따라 이미지 내용을 전달해서 비디오 영상을 생성하는 단계로 나눠 진행합니다. 이 프레임워크는 사용자가 직접 모션이나 영역을 지정해서 특정 움직임을 원하는 대로 조절할 수 있습니다. 다른 영상 생성 모델과 달리 큰 움직임과 시점 변화가 있는 경우에도 훨씬 더 일관된 영상을 만들 수 있으며 영상이 한 형태에서 다른 형태로 자연스럽게 변화하는 것을 지원합니다.
|
|
|
사진 : Motion-I2V 개요 (상), 모델 적용 예시 (출처) |
|
|
인공지능 서비스의 배포와 운영 시 도움이 필요하신가요?
(주)소이넷은 인공지능 서비스를 제공하는 기업들 가운데 서비스 배포와 운영에서 어려움을 겪고 계신 곳에 도움을 드릴 수 있습니다.
혹시 구독자님의 회사는 다음과 같은 어려움을 겪고 계시지 않나요?
- AI 모델을 개발하고 학습 후 서비스를 위한 성능(Accuracy)은 달성했는데, 정작 최적화 엔지니어가 없어서 어플리케이션, 서비스로의 배포를 위한 실행최적화를 못하고 있어요!
- AI 서비스를 이미 제공하고 있지만, 비싼 클라우드 GPU 서버 인스턴스 사용료가 부담이 되네요. 흠... 경비를 절감할 수 있는 방안이 없을까?
- 서비스에 적합한 공개 SOTA 모델이 있지만 그대로 가져다 쓰기에는 우리 쪽 어플리케이션에 접목하기도 어렵고 운영 비용도 많이 들 것 같은데 어쩌지?
- 서비스에 사용되는 AI 모델을 통합적으로 관리, 배포, 모니터링을 하고 싶은데 그렇다고 비싸고 너무 복잡한 솔루션을 쓸 수는 없고 어쩌지?
- 비즈니스 도메인 기업이긴 한데 자체로 인공지능을 적용하기에는 기술적인 난이도도 있고... 어디 함께 공동 솔루션을 개발할 곳은 없을까?
그렇다면 언제든 아래 연락처로 문의 주세요. 함께 해결책을 고민해 드리겠습니다.
|
|
|
오늘의 뉴스레터는 여기까지
구독자님,
다음 번에도 재미나고 흥미로운 소식을 가지고
다시 찾아뵙겠습니다. |
|
|
구독해 주시면 좋은 소식, 정보로 보답하겠습니다. |
|
|
주식회사 소이넷
sales@soynet.io
경기 성남시 분당구 성남대로331번길 8 (킨스타워) 1503호
대표전화 : 031-8039-5377
|
|
|
|
|